Current developments in the field of open web technology (see chapter 3.2.2) give rise to fundamentally new ways of thinking and building time-based media on the web. The questions that arise are how this process influences film in general and how the particular functionality can be used to explore new forms of web-based film and hyperlinked video. However, while concrete implementations of hypertext systems evolved out of a certain community, the origins of hypervideo systems are difficult to name and depend on incoherent definitions. As a result, particularly web-based implementations are entitled “hypervideos” because they consist of some kind of interactive film. Even though some existing applications fit partly into the different hypervideo definitions, most of them do not go beyond transferring the simplified concept of web hypertext to film. The original hypertext ideas (see chapter 2.2.1) have been subject to research in many disciplines, including cognitive science, comparative literature, digital humanities and the emerging field of web science. A profound evaluation of the properties and functions of a link resulted in the conscious use of technological possibilities (e.g. in electronic literature) as well as the definition of generalized models for hypertext and hypermedia.
Due to technological restrictions regarding the use of time-based media on the web, respective hypervideo systems have been developed in other surroundings or as foreign objects (plug-ins) of the web. Now, that video and audio finally became a first class citizen of the prevailing hypertext system, it seems that current developments lack any reference to the hypertext community. There is a clear need to integrate existing hypermedia research into the process and to design web-based film with reference to the origins of the hypertext idea. As most of the initially proposed properties of a link did not find their way into the web’s implementation of hypertext, now is the time to integrate some of them into web-based hypervideo.
The basic idea behind hypertext is the associative interconnection of document fragments. By creating these interconnections, the user (or author) automatically collects documents. The expanding collection thus comes into existence through materialized associating. But in a broader sense, these interconnections have existed before and can be found in between any form of cultural collaboration. The archive, as a cultural institution, aims to preserve these references by storing the respective documents. Inside any archive, the links in between documents still exist in form of the reason for their storage, that is, the story of their interconnection. In a media-theoretical context, one could therefore state that an archive is in its “interlinkedness” already a hypermedium. It just does not fulfil the properties of hypermediacy (see chapter 2.1.2) because the inner methodology and intertextuality stay invisible. In this thesis, the medium film will be explored as a way to re-visualize the hidden narratives❉ within the archive. In the concept that will be proposed, particular documents are embedded in video sequences, which shall allow the film surface to become an archive interface. The video sequences themselves are again interconnected to facilitate the non-linear, film-based exploration of multiple document collections. What shall emerge is an interface that interconnects documents through filmic links.
Concerning web-based hypertext, there is a wide range of research on intertextuality, link structure, creation and reception of the medium. If video can work like hypertext, what are the media-specific possibilities and boundaries? Moving images are in many terms different to text, which could make some hypertext methods obsolete and at the same time offer new chances for interconnected time-based media. Conclusively, the historical accident of source code availability in web hypertext may have to be explicitly “arranged” and defined for a hypervideo architecture.
To allow the exploration of hypervideo as archive interface, the properties of archives as cultural institutions will be further displayed.
The origins of occidental archival practice can be found in the Athenian archives of ancient Greece (Derrida, 1996). Before the first central archive was built by the end of the 5th century B.C., official documents had only been stored in decentralized arkheia❉ (Ebeling, 2009). An arkhaion was administrated by an archon, who lived in the archive and who was “accorded the hermeneutic right and competence” (Derrida, 1996, p. 2). The archons had the “power to interpret the archives” (ibid., p. 2). In the tradition of the arkhaion, today’s definition of the archive term describes the archival practice as well as the institution of the archive (Encyclopedia Universalis, cited in Ricoeur, 2009, p. 123).
In a 1994 lecture at the international conference Memory: The Question of Archives Derrida (1996) formulates a fundamental critique on the concept of the archive as an objective institution. His thesis is based on the Freudian model of memory. In this model, Freud describes the functions of the psychic apparatus and the relationship between perception and memory on the basis of the Mystic Pad❉. According to Freud, the written word is an external storage medium of the human memory apparatus (Derrida 1996). Similar to the wax tablet of the Mystic Pad, the human mind can save a continuous stream of information. Based on psychological processes, information that is no longer required (or wanted) to be present is “archived” in the subconscious. Referring to the Jewish historian Yerushalmi, Derrida (ibid.) examines these mechanisms using the example of the divergence between history and historiography in Jewish Remembrance Culture. Jewish historiography is thus shaped by religious motives, which leads (intentionally or not) to a selective maintenance and storage of historical content. Derrida (ibid.) compares these possibilities of selection and interpretation with the power of the archons over “their” archives and defines it as “archontic power” (p. 3) or “power of consignation” (ibid.). The archive itself is therefore described as an instrument of power for those who rule it. According to Derrida, the purposes and properties of archived artefacts are also influenced by the inner structure and economy of the archive, as well as by the act of archiving itself. When a document is declared an archival record, the meaning and the function of what was intended to be documented already changes and the artefact becomes an alienated repetition of the original. Inside the archival economy the document becomes part of particular mechanisms that derive from the structure and the hierarchy of the archive, which change the meaning again (ibid.).
Derrida’s critique can therefore be interpreted as a statement that the archive, as a concept of preservation, in the strictest sense does not work because it is constantly operating against itself. But his assumptions can also be seen as a demand to make the methodologies of archives visible and so to distribute the archontic power through transparency. Derrida also notes that there are no strict boundaries between the inner methods of an archive and the outside world where the documents come from. In this context, the archive is a ubiquitous cultural concept and not limited to institutions or storage spaces.
In contrast to libraries, which are designed to support document retrieval, the organizational concept of archives follows operations of storage❉. This circumstance influences the possibilities and methods of document access. While libraries provide in their structure a particular ontology that can be reflected in an interface layer, the inner structure of archives depends on methodologies of accumulation. The basic property of any interface is that it provides (mediated) access to the contents beyond it (Bolter and Grusin, 1999). In this definition, the archon would serve as interface for his arkhaion (see previous chapter) just like orientation signs would be part of a library interface. Bolter and Grusin (1999) as well as Bolter and Gromala (2003) evaluate the relationship of interface and content on the basis of immediacy and hypermediacy as media-theoretical concepts. The less visible an interface, the more it functions as a window and follows the concept of immediacy. An entirely transparent interface “would be one that erases itself, so that the user is no longer aware of confronting a medium, but instead stands in an immediate relationship to the contents of that medium” (Bolter and Grusin, 1999, p. 24). When the properties and methods of the interface become visible as a medium, it functions as a mirror and can be classified as hypermedia (Bolter and Gromala, 2003). Concerning the common rule that interfaces need to be invisible (Norman, 1998; Nielsen, 1999), Bolter and Gromala (2003) state that “in fact the goal is to establish an appropriate rhythm between being transparent and being reflective” (p. 6).
The previously described properties of an archive (see chapter 2.1.1) implicate the existence of an inner methodology and a document context that represent the reason for its storage. When the document is retrieved through a transparent interface, the (original) context remains invisible. An interface that can reflect the invisible interconnections inside the archive fulfils the criteria for both, immediacy and hypermediacy. When the interface enables the integration of additional connections, it does not only fulfil properties of hypermediacy, but becomes itself an independent hypermedium.
Associative references inside document collections do neither result from specific technological environments nor from cultural phenomena. These conditions only influence how explicit references are (made) visible. Looking at the entirety of media content, the creation process is never free from external influences by existing fragments of information. In this context the emergence of media content is always a collection of quotations that can be traced back to a certain origin, depending on a particular philosophy or world view. This phenomenon is described by Ted Nelson (1993) as literary paradigm:
A literature is a system of interconnected writings. […] These interconnections do not exist on paper except in rudimentary form, and we have tended not to be aware of them. We see individual documents but not the literature, just as people see other individuals but tend not to see the society or culture that surround them. (ibid., p. 2/9)
The question that remains is how many of these implicit references are explicitly made visible and if they are part of an organizational concept. When Nelson (1993) founded Project Xanadu in 1960, he envisioned a system that is capable to manage the creation, storage and reception of document units, based on their origin. When new units are created, they “can be built from material in previous units, in addition to new material” (ibid., p. 0/5). Consequently no single part of a unit exists more than once in the system, because it would be included by reference (“transclusion”, ibid., p. 5 of preface).
Figure 1 : Screenshot of the XanaduSpace 1.0 Prototype
Nelson (1993) also imagined a deep versioning system to manage the creation of resources. While the described parts of the Xanadu-Project were only built as a prototype, the concept of links in between document fragments (“portions of units”, ibid., p. 0/6) influenced all following hypertext systems, including the World-Wide-Web. The origin of Nelson’s idea can be found in the Memex-concept described by Vannevar Bush in 1945. Regarding links, Bush (1945) imagined a system that would allow the creation of “trails” (p. 8) through fragments of personal documents. Those trails would be created by the user and were meant to reflect the way the human brain stores and retrieves knowledge through associative connections. The trail concept also comprises the notion of the direction of a particular reference as well as the possibility to link from one fragment to several other fragments and vice versa. Nelson et al. (2007) later interpreted Bush’s concept of trails as describing transclusions, rather than links.
Tim Berners-Lee and Robert Cailliau (1990) proposed the use of hypertext “to link and access information of various kinds as a web of nodes in which the user can browse at will” (para. 1) in a project named the WorldWideWeb. In today's implementation of the web, the original properties and functions of a link have been simplified and reflect only a small part of the original hypertext concept.
Before the web became the prevailing hypertext system, the general idea of functional intertextuality had been explored by several authors as a way to enable non-linear storytelling❉. The genres that emerged from these approaches, namely hypertext fiction (hyperfiction), hypertext poetry and interactive novel, make use of hypertextual link structures to allow non-linear navigation through different narrative paths (Landow, 2006)❉. In web-based hypertext, the link structure on the code layer is an integral part of the hypertextual representation in the browser. As the architecture allows only one type of links, the reference on the literary layer is neither metaphorical nor implicit. The hyperlink rather functions as a direct and explicit connection.
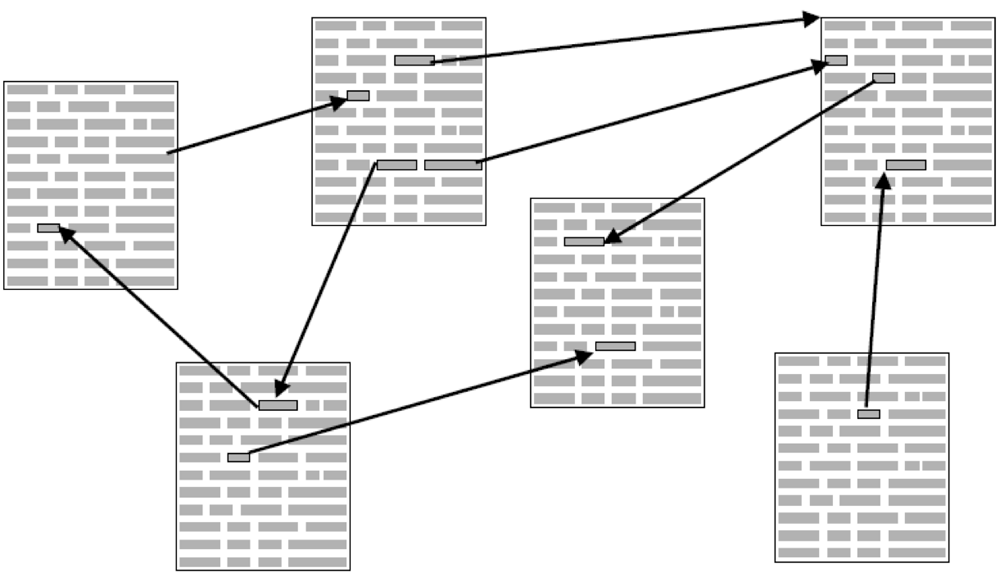
Figure 2: Typical design of a hypertext-structure (Finke, 2005, p. 11)
In hypertexts, classic structuralist narrative techniques, where one central theme leads from one source through one way to one destination/insight, are broken in small parts (Landow, 2006). Through the limitation of choices and the concept-based use of interconnections, the reader can be led through a network of story fragments. The virtual intertextuality of print culture is made explicit and visible (see previous chapter). In terms of navigation, the reader has to decide at every node which path to take (narrative of possibilities, Douglas, 1991). Hereby exists neither one “right” way nor one direction, which means that hypertext reading can also imply back steps and repetition of story parts in another context (Landow, 2006). As the reader “assembles” his own path through the story, which may or may not have been part of the initial concept, he or she slips into the role of a co-author (ibid.).
The authoring process of hypermedia works can involve three different entities: one author, several collaborators and the recipient. According to Simanowski (2001), the traditional idea of the singular author can still be preserved in hypermedia, at least in a way that enables him or her to create concluded but not finished works. However, the poststructuralist view of authorship reduces the relevance of the authors’ intentions (Barthes, 1978; Foucault, 1980) and new media theory on remix culture extends these assumptions by the notion of collaboration models:
[...] think of medieval cathedrals, traditional painting studios which consisted from a master and assistants, music orchestras, or contemporary film productions which, like medieval cathedrals, involve thousands of people collaborating over a substantial period of time. In fact, if we think about this historically, we will see collaborative authorship represents a norm rather than exception. (Manovich, 2002, p. 1)
The collaboration process automatically leads to implicit links in between fragments of works. With or without the intention of particular collaborators an invisible web of reciprocal reference evolves. In the field of new media, these specific properties are used to let the collaboration process itself be part of the works (“remix culture”). In their study of an online video remixing community, Diakopoulus et al. (2007) identify four components of authorship: “originality, authority, intertextuality, and attribution” (p. 1). Originality here refers to the traditional view of the author as a genius, whose work is dependent on his or her individuality. In the field of film, this opinion is supported by advocates of “auteur theory” (ibid., p. 3). The property authority describes the power of the author to influence potential users or co-authors, for example through the limitation of technological possibilities or the reduction of time and space within a narrative. Intertextuality is defined by Diakopoulus et al. (2007) as the component that influences how visible the references and sources of a particular work are made. This definition is based on the assumption that the authorial construct always consists of outside influences that the author experiences inside a certain society or culture, formerly described by Nelson (1993) as the literary paradigm (see chapter 2.2.1). Along with the attribution of individual authorship, the previously referenced components form a general concept of authorial creation (Diakopoulus et al., 2007).
Finally, several hypermedia theorists advocate the function of the recipient as a co-author (Wirth, 1997; Simanowski, 2001; Landow, 2006). The hypertextual properties described in the previous chapter enable the reader to take decisions that influence his perception of the narrative. By these decisions the recipient authors his own narrative within an overall system of the respective narrative architecture. The reader is thus an inspector of narrative choices and through the taken decisions becomes a co-author of the presented stories.
The described attributes of hypertext have also been part of a film-based exploration of the hypermedia concept, namely hypervideo❉. Although hypervideo history is commonly told in conjunction with other hypertext and hypermedia systems, it will be limited in the following to hypervideo concepts.
An early example of a hypervideo system is the Aspen Movie Map from 1978, which allows navigating through the city of Aspen by the user-driven selection of video-sequences (Lippman, 1980). In 1996, Shawney et al. presented HyperCafe, a hypervideo implementation that is based on a virtual café situation where the user can actively navigate through different dialog scenes and so experience his or her own narrative.
Figure 3: Video Collage Interface of HyperCafe (Shawney et al., 1996, p. 4)
The authors described the HyperCafe prototype as “an illustration of a general hypervideo system” (ibid., p. 2) and introduced media-specific characteristics that significantly formed future hypervideo research (see next chapter). Although usually not mentioned in hypervideo history, the invention of the DVD (1995) for the first time enabled the application of basic non-linear narrative techniques to a widespread time-based medium in forms of alternative endings, interconnected audio commentaries and additional scenes❉. In 2003, Shipman et al. presented the hypervideo editing system Hyper-Hitchcock (2003a), which allows the non-linear interconnection of entire video scenes and thus partly followed the approaches described by Shawney et al. (1996). In the following years, hypervideo research concentrated on the development of applications that make use of sensitive regions or hotspots to interlink outside resources. This process led to the emergence of additional authoring tools, but also to the commercialization of hypervideo❉. From the very beginning, hypervideo was also subject to research in the fields of education and knowledge building (Locatis et al., 1990). These fields later became the main research area for hypervideo (Guimarães et al., 2000; Zahn, 2003; Schwan and Riempp, 2004; Finke, 2005).
Current developments in web standards allow for the first time the integration of video and audio fragments into a native web environment (Sadallah et al., 2011). These possibilities led to the first interactive films created under the sole use of open web technologies (Watercutter, 2011). In terms of storytelling, current events indicate the emergence of interactive film as a medium for citizen journalism (e.g. Mozilla Drumbeat: Unlocking Video Challenge). Even though most existing projects are not yet designed as hypervideos, their technological environment could form the basis for the future of hypervideo on the open web.
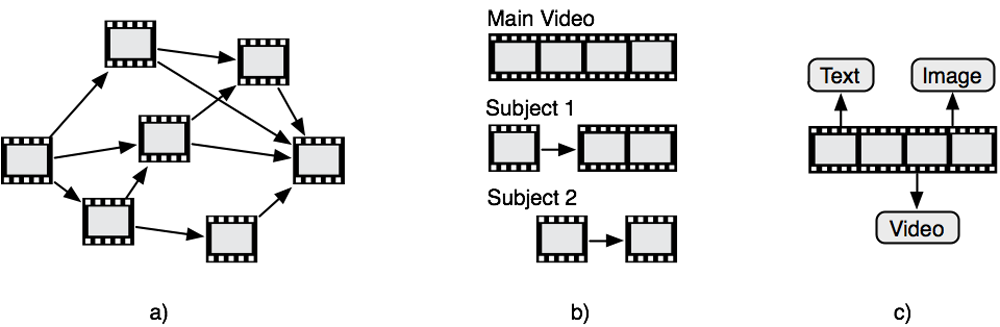
In contrast to other hypermedia-concepts, the basic instance of hypervideo is always a video-sequence. The fact that even the shortest sequence is itself always linear brings about certain limitations (Zahn, 2003). Nevertheless a basic hypervideo structure consists of time-based internal and external links that form a non-linear overall concept. Zahn (ibid., p. 11) distinguishes homogenous hypervideos that contain only video fragments and heterogeneous hypervideos that also consist of other media types❉. The information structure of hypervideo documents is classified by the author in open, open-hierarchical and hierarchical types:
Figure 4 a-c: a) “open” type – network of scenes; b) “open-hierarchical” type - subject hierarchy; c) “hierarchical” type – multimodal footnotes (adapted from Zahn, 2003, p. 20)
Zahn defines hypervideos of open type as networks of associatively connected fragments, while the hierarchical type of hypervideos is rather based on the linear content hierarchy of a main video. Hypervideos of open-hierarchical type are finally built of fragments that are dynamically interconnected based on an overall subject-based hierarchy of a main video.
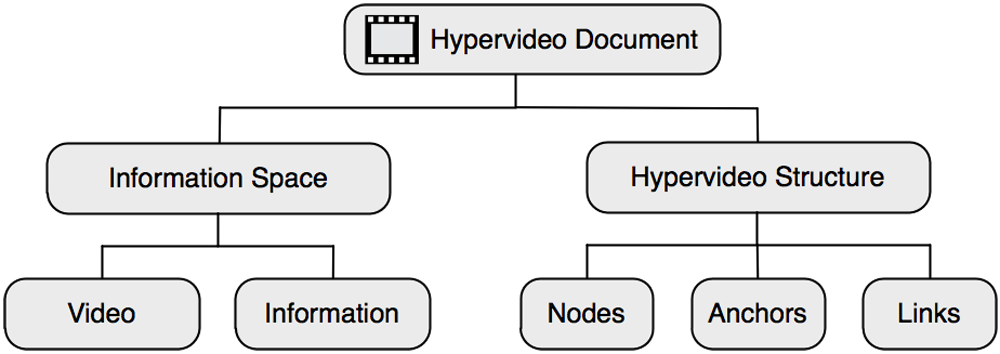
Finke (2005) further subdivides a single hypervideo document into “information space” (p. 25) and “hypervideo structure” (ibid.):
Figure 5: General structure of a hypervideo document (adapted from Finke, 2005, p. 25)
The Information Space contains the video sequence and additional information (e.g. in forms of annotations). The Hypervideo Structure consists of nodes, anchors and links. A hypervideo node is a potentially linkable video fragment. Through an anchor and a link, the source fragment can be connected to its destination. Besides the temporal position of the node and the reference to one or more destinations (links), an anchor can also include information on the spatial position within the video frame (Finke, 2005). The concept of temporal and spatio-temporal links has previously been described by Shawney et al. (1996).
The frame-based nature of film raised discussions on the units that should be the basis for time references. In the Amsterdam Hypermedia Model (AHM), Hardman et al. (1994) describe “atomic components” (p. 58) and “composite components” (ibid.) that facilitate multiple reference levels of source- and destination context. Shawney et al. (1996) introduce “narrative sequences” (p. 5) that contain at least one scene as a film-based reference model. Finke (2005, p. 27) divides linkable units into video sequence, video scene and video object. Video sequences hereby represent a concluded information unit that can only be referenced in its entirety. A video scene is a time-based fragment of a video sequence, which can be independently referenced. Conclusively Finke (ibid., p. 27) defines a video object as a linkable semantic region inside the frames of a video scene. In addition to previous link-based models Sadallah et al. (2011) propose a Component-based Hypervideo Model (CHM) that includes “Event and Action” (p. 3).
Prior to the recommendation of the HTML5 standard, web-based hypervideo has only been possible through browser plug-ins (Sadallah et al., 2011). While the descriptive languages that support hypervideo are based on open standards (Finke, 2005), many of the existing player environments have been built with proprietary technology. Examples for these developments are projects that apply the open Synchronized Multimedia Integration Language (SMIL) as basis for applications that run in a closed RealPlayer environment❉.
As previously noted, the interface layer of hypermedia systems does not only provide access to contents. The interface rather is an integral part of the underlying information structure, in the sense that the methodology of the medium becomes visible on its surface (see chapter 2.1.2). However, while hypertext on the web usually consists of discrete media (text, image, graphic), the basis for hypervideo is continuous media (video, audio, animation)❉. In a hypervideo environment, the visualization of links is dynamically oriented on the temporal structure, as well as on different spatial positions within the interface (Shawney et al., 1996). Hypervideo links can therefore only be designed with respect to the medium film and its very own properties (Zahn, 2003). This is particularly relevant to interactive elements that overlay the film (hotspots or sensitive regions). According to Michon (1993), hotspots should suggest the user interaction with an object in the medium, rather than with its interface❉. Finke (2005) evaluates different visualization methods for sensitive regions: outline, transparent shape and a combination of both methods (see figure 6).
Figure 6 : Design concepts for sensitive regions (Finke, 2005, p. 96)
The author furthermore describes three types of filters that can be used to distinguish a transparent shape (figure 6b, c) from its context: brightness, contrast and colour (ibid.).
An unsolved question in the hypermedia field in general is how much of the destination and source of the link should be integrated in the interface of the respective medium. This issue can be traced back to the discussion of different link properties by Nelson (1993). The web-based implementation of hyperlinks only provides the possibility to “jump” from one source to one destination. While in hypertext the comparatively homogeneous presentation of words facilitates browsing, the heterogeneous appearance of moving images entails problems in terms of continuity. The immersive qualities of film can thus be disrupted by the immediate disappearance of context when the user follows a link.
Figure 7 : User Interface of the VisualShock Movie System (cited in Finke, 2005, p. 61)
Common approaches to this problem are the integration of the link destination into the hypervideo interface as in the VisualShock Movie System (see figure 7) and the visualization of the overall link structure in separate view modes as in the Hyper-Hitchcock editing interface (see figure 8).
Figure 8 : Spatial/navigational structure in Hyper-Hitchcock (Shipman et al., 2003b, p. 1)
As the basic information structure consists of interconnected film, continuity can also be supported by short fragments that visually interconnect two video nodes (“navigational bridges”, Shawney et al., 1996, p. 2). Finally, a homogeneous hypervideo experience can only be designed by integrating the interface conception already in the film creation (Shawney et al., 1996).
In contrast to hypertext, the hypervideo-term has become a universal description for several heterogeneous multi- and hypermedia concepts (see chapter 2.3.1). Existing hypervideo implementations lack common media-theoretical roots, an overall conceptual core and in particular accessibility. In the field of web-based video, the “Open Video Alliance” (Kane, 2009) advocates open source video in forms of accessible and distributed standards. The term “open hypervideo” is thus proposed as part of common hypervideo definitions to allow a more specific description of hypervideo works that are built within the use, study, remix and share-philosophy of the web (see Surman, 2011). Referencing the original hypertext ideas (see chapter 2.2.1), the basic principles of open hypervideo are fragmentation, openness and non-linearity. With a strong focus on film as structural component, these principles shall form an overall organizational concept.
In order to freely interconnect multimodal contents, the documents need to be as fragmented as possible. While fragmentation is one of the overall principles of hypermedia, this property can also be found in the production process of conventional linear film. Prior to the finalization of a film, it consists of a concept (the script), which outlines various small scenes, narrative connections, transitions, moods, time shifts or internal references. During production and post-production, those fragments are ordered and provided with particular audio-visual effects. Just before the final rendering, the entire film exists in form of accessible fragments inside a particular editing environment. This circumstance leads to the principle of openness. In an open environment like web-based hypertext, the source code enables the preservation of accessibility even after the work is considered concluded by the authors. In terms of narrative connections, openness on the code layer allows the conception of works that explicitly leave space for co-authors and readers to remove, remix or add fragments. Film-based works containing such properties can be classified as hypervideos of open type (Zahn, 2003; see also chapter 2.3.2). The open hypervideo definition therefore implies besides an accessible code layer a non-linear overall concept. The principle of non-linearity as applied in hyperfiction involves a non-linear design of the narrative structure (Landow, 2006). Even though it is possible to add non-linear interconnections or annotations to previously linear works, the basic information structure of the narrative would still be linear and thus bound to the initial limits in time, space, characters and subjects.
While open hypervideo will be described as a general hypervideo concept, concrete proposals concerning the technological environment are based on open web technologies.
The origins of the hypertext idea can be found in a document- and knowledge management background (see chapter 2.2.1). In Nelson’s notion of the literary paradigm (1993), ubiquitous but mostly invisible links in between written words form a “system of interconnected writings” (p. 2/9). Hypertext in this context is the infrastructure as well as the interface for document access. The proposed architecture for open hypervideo is entirely built on interconnected film as infrastructure and interface. In reference to the Memex concept (Bush, 1945), the open hypervideo interface serves as access point to a document archive. The components that will be elaborated are based on the principles of fragmentation, openness and non-linearity (see previous chapter).
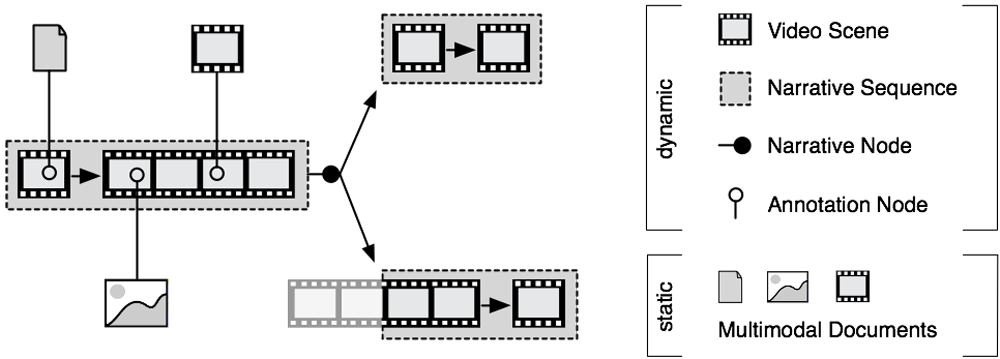
Based on Shawney et al.’s (1996) conceptual hypervideo framework, the main architectural units are “narrative sequences” (p. 5). A narrative sequence contains at least one video scene and represents a concluded information entity (see figure 9).
Figure 9 : Components of an Open Hypervideo Architecture
Other than in the model by Shawney et al. (1996), a video scene is not bound to the start- or end-point of a specific video file. Different fragments of the same scene can thus be included in several narrative sequences, provided that the sequence itself still functions as a concluded narrative unit. As video scenes can in some cases also be played backwards, narrative sequences are interconnected through narrative nodes at the beginning or the end of a sequence. The narrative node hereby always defines the conclusion of a narrative sequence and presents at least two possible destination sequences. When a narrative node is included within the time frame of an existing narrative sequence, the sequence is split at that point into new narrative sequences, while one node destination is the related split part. Narrative sequences can also be used to interconnect visually heterogeneous information units with a filmic link (similar to Shawney et al.’s use of “navigational bridges”; 1996, p. 2). Video scenes can be connected through temporal and spatio-temporal annotation nodes with multimodal documents. The basis for time references is hereby the video file, even if only a fragment is part of the particular narrative sequence. In contrast to a narrative node, an annotation node supplements the narrative with additional documents and is not part of the basic information structure.
The advantage of the proposed model lies in the clear distinction of narrative architecture and annotation-layer. In an open hypervideo environment, associatively connected narrative sequences function as interface for document access. The hypervideo architecture can thus be weaved on top of a document collection, providing previously invisible reciprocal references in between documents through filmic narratives. In contrast to other common hypermedia models (see chapter 2.3.2), the document archive itself is static and not part of the dynamic open hypervideo structure. The model therefore facilitates the implementation of an dynamic archive on the presentation layer, without alternating the archive’s own documents and methodology (see chapter 2.1.1). Nevertheless, the open hypervideo concept enables interface authors to reflect the mechanisms and methods of a particular archive on the hypervideo surface. Finally the open source code of the hypervideo structure itself leads to a transparent and retraceable view on the provided methodologies of document access.
Through current developments of web standards, in particular HTML5 Video (Hickson, 2011) and Media Fragment URI’s (Troncy et al., 2011), the web is about to become the most suitable technological environment for the proposed hypervideo concept. The possibility to attach links and functions to specific points of time in a video enables for the first time the implementation of a hypervideo idea that relies exclusively on open web technologies.
In terms of the fragmentation principle (see chapter 3.1), state-of-the-art resource indicator schemes facilitate the reference of temporal and spatio-temporal video fragments (Troncy et al., 2011) and thus give way to the broad use of a whole new type of link on the web. Referencing Media Fragment URI’s through Inline Frames (iFrame) could in addition facilitate a partial implementation of Nelson’s “transclusion” concept (1993, p. 5 of preface) for time-based media. As the code layer of the open web is accessible and “remixable” at runtime, the previously proposed principle of openness (see chapter 3.1) can easily be integrated in a web-based open hypervideo implementation. In conjunction with the canvas element, the visual representation of HTML5 Videocan be manipulated live in the browser. Together with the transition property of CSS3 and the three-dimensional support of WebGL, the new standards enable an externalisation of filmic effects, animations or dynamic interface changes from the closed environment of pre-rendered film to the open runtime layer of the web. Additionally, the open source “development” of film permits the dynamic assembly of media fragments based on user interaction or programmed logic. Even though basic hyperlinks on the web cannot interconnect multiple resources at once, the concept of narrative nodes (see previous chapter) can be implemented with open web technologies through the custom creation of respective functionalities. The HTML5 Media Framework PopcornJS finally simplifies the integration of several web services and APIs into time-based media (video and audio), as well as the connection of events to specific points of time. Although not specifically designed as a hypervideo environment, the framework allows a straightforward management of time-based presentation and interaction.
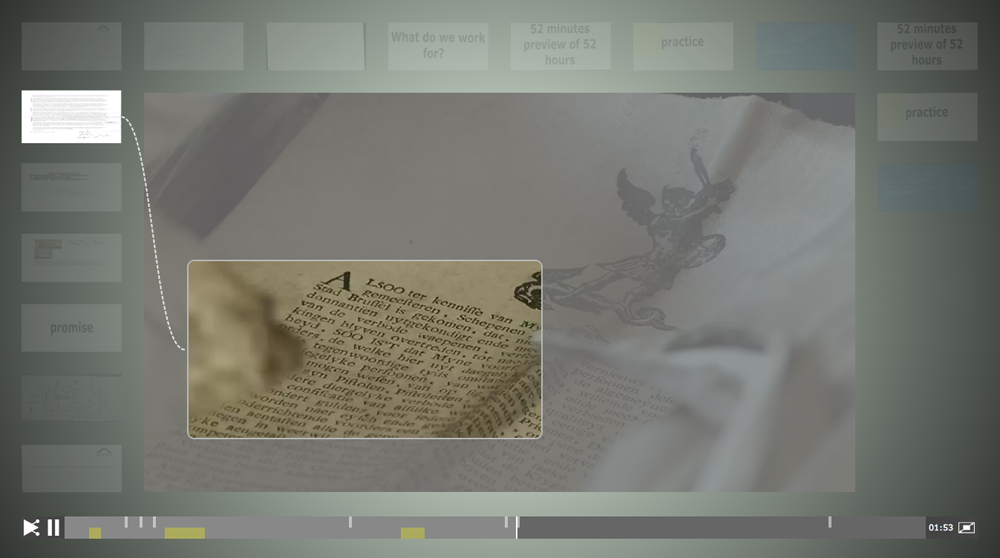
The video scenes within an open hypervideo structure are not perceived through additional interfaces. In reference to web-based hypertext, hypervideo sequences are their own interface. At the very basis, film frames are the constantly changing interface background. As nodes and annotations refer to specific temporal positions within the film representation, hypervideo links are in a continuous mutual relationship between transparency and visibility. The timeline, commonly the only instance providing contextual information, could therefore establish as the main visualization entity for otherwise invisible hypervideo elements. In a hypervideo system that is primarily designed to enable a film-based perception of annotated documents, the annotation node is also an important access point to the document archive. A hypervideo interface should in this context imply the schematic visualization of the referenced documents at all times (see figure 10). In addition, the hypervideo should enable document preview and access within the film context.
Figure 10 : Design example for interactive timeline and hotspot visualization
The heterogeneous appearance of the film background complicates the definition of general design rules for hotspots or sensitive regions (see chapter 2.3.3). There are two basic approaches to this problematic. On the one hand, the appearance of hotspot links can be programmatically adapted at every instance to the visual properties (color, brightness, contrast) of the current video frame. This approach would involve the continuous calculation of average values for every hotspot frame. A more generally applicable solution would be to change the visual appearance of everything but the hotspot (see figure 6). Semantically, this approach also has the advantage that the referenced video object (see chapter 2.3.2) is not altered.
The main question in hypervideo interface design is about the prominence and the preservation of film-specific properties in an interactive environment. In reference to Bolter and Grusin’s remediation thesis (1999), hypervideo can be interpreted as a new form of film that evolves through the integration in another medium, in this case the web. Nevertheless, the immersive qualities of traditional film gain their power also from the fact that they do not allow anything else than the passive perception of the medium. If the goal of a hypervideo system is to allow document access through filmic narratives, interface designers should take the film as well as the annotated documents into account. An approach to an appropriate rhythm between film and interactive elements is to divide different levels of immersion and interactivity into multiple view-modes and thus leave the choice to the recipient. As in Shawney et al.’s HyperCafe-prototype (1996), the conscious conceptual design of film fragments already as a hypervideo interface can lead to an overall immersive hypervideo experience, despite or even because of interactivity.
Particularly for the proposed open hypervideo system, design rules and interaction schemes must be contagious enough to enable a homogeneous experience and unfinished enough to allow co-authors the extension and alternation of contents. Therefore important interface elements should not be thematically bound to specific content elements. Like the open hypervideo architecture (see chapter 3.2.1), the code-layer of the interface needs to be accessible and open for manipulation. This requirement leads directly to the question whether or not there is a need for an editing interface. The open architecture allows full control over presented contents and interface at source-code level. Nevertheless the ability to take control depends on the author’s computer literacy. An editing interface on the one hand simplifies content creation, but on the other hand entails the probability that the author is not able to question or rethink media-specific properties and methods. Following Rushkoff’s Program, or be programmed principle (2010), an editing interface for the proposed open hypervideo system should support but not replace source code creation.
While strategies of non-linear narrative are common in fields of hyperfiction, interactive games or transmedia storytelling, those have not been broadly applied to plain hypervideo works. The difference between general hypermedia concepts and those that are bound to a specific medium can be seen at the example of pure hypertext. Through the focus on specific properties of written words, several genres of electronic literature have been subject to research in “traditional” comparative literature. The outcomes of this research were then often new approaches in the field of electronic literature (Landow, 2006).
The open hypervideo concept enables the deep analysis of media-specific properties. This circumstance relieves the development of new approaches within the field of “traditional” film theory, which could then reflect back to the hypervideo idea. As in hypertext history, these new approaches could be the basis for new forms of non-linear storytelling that concentrate more on the very own properties of film. Assuming the literary paradigm (Nelson, 1993) is not bound to written words but can also be extended to moving images, a hypervideo environment could enable the functional interconnection of story parts that are already designed in a non-linear overall concept (e.g. The Sopranos series: Oliver, 2011). The principle of openness (see chapter 3.1) further allows the collaborative interconnection of stories, as well as the alternation of existing hypervideo works in the remix culture of the web.
The proposed use of open hypervideo as archive interface implicates the collaborative annotation with resources that supplement the story. What emerges is a hypervideo interface that functions as a non-linear narrative environment inside a document archive. The way that those documents become associatively (Zahn, 2003; see also chapter 2.3.2) and successively (time-based) interconnected on the storyline has several similarities to Bush’s concept of “trails” (1945, p. 8). In architectural terms, interconnected narrative sequences (see chapter 3.2.1) become multiple film-based paths in between annotated documents. Even if the hypervideo is not perceived through its interface, the documents are ordered by a particular narrative logic. This could enable an entirely new organizational paradigm, which facilitates to order information “by appearance in the narrative” or “by a particular narrative path”, rather than by document-specific attributes like date or title.
Research in cognitive science has shown that information can be remembered best when being perceived through multiple senses (Dual-Coding Theory: Paivio, 1986) and associated concepts (Spiro and Jehng, 1990). A non-linear audio-visual architecture in combination with an explanatory narrative could thus prove as an efficient model for knowledge building and –sharing. The principles of fragmentation and openness in the proposed hypervideo concept (see chapter 3.1) facilitate a transparent knowledge management environment, as well as the collaborative design of information architecture and representation (interface) at source code level.
The non-linear interconnection of documents on the web allows a perception of document fragments based on the system-specific logic. However, in times of databases, document access is a task that is commonly solved by search methods. Considering hyperlinks as narrative paths through the web’s “docuverse”❉, most retrieval methods break with the overall concept in order to allow faster and more sophisticated access to certain bits of information. But in the field of information retrieval, there is at least one condition that needs to be fulfilled to achieve one’s individual search task: the user has to know what he or she is looking for (Marchionini and White, 2008, cited in Hearst, 2009). In an exploratory search (Wilson et al., 2010), this often unfulfilled condition is used as a chance to guide the user in the searching process and present him or her alternative paths to follow. By taking these paths, the information space can be explored and potentially leads the user by (guided) serendipity to a satisfactory result. The initial result is hereby only the starting point for exploration.
Exploratory search paths can be constructed of particular database operations, linked-open-data (Waitelonis and Sack, 2011) or an associatively connected web of common hyperlinks. In a hypervideo environment, these paths could also consist of interlinked film sequences, which do not represent results but rather lead through an agglomeration of documents. A corresponding search interface could provide the user with results that are concurrently entry points to a system of narrative exploration. In addition to an interlinked or semantically interlinked information space, this system would unite exploration and immersion in a less directed surrounding. An in-depth description of the corresponding user type is provided by Dörk et al. (2011) through the introduction of the information flaneur.
The described hypervideo interface and the underlying document archive exist within particular methodologies of document collection, representation and access (see also chapter 2.2.1). The accessibility of source code in the open hypervideo architecture enables artists to make the methods of the interface and the attributes of “archontic power” (Derrida 1996, p. 3) in the archive part of their works. The artistic use of open hypervideo could thus open the institution and the space of the archive for discussion. Through artistic practice, the institutional routine and the gaps of the archive can become visible. Winzen (1997) describes the properties of these practices using the example of artistic collection:
While a conventional collection expands, fills up and complements the theme and subject matter of this particular collection […], artistic collecting proceeds more open, less wittingly, more reflective and fragmented. Works of art that consist of a collection draw their power from the fact that they thematize how paradox collecting itself is. In their practice, artists initially collect as anyone else would collect. But they also pay attention to the backsides and edges, the absurd and neglected of collecting, storing and archiving. (Ibid. p. 10, own translation❉)
Artistic practice thus allows a self-referential presentation of archive contents. The inner methodology can be presented as an independent medium and is no longer bound to its own laws. In a media-theoretical context, the archive could become itself a hypermedium through a visible and functional methodology (in reference to Bolter and Grusins hypermediacy-definition, 1999). Furthermore, the technological and cultural properties of the web, as environment for open hypervideo, can be part of self-reflective artistic research.
The previous chapters provided an approach towards novel film-based interfaces within the environment of the open web. Through the interdisciplinary examination of hypertextual properties and their implications on the proposed hypervideo-architecture, the value of open hypervideo for multiple use-cases could be described. The continuous reference to the archive as the preferred document environment as well as a ubiquitous cultural surrounding made it possible to elaborate the requirements on methodology and design of the interface layer for document management purposes. However, it also became clear throughout the considerations on film as interface that the specific properties of the medium require a more profound analysis of contemporary film theory than could be provided in this thesis. This applies in particular to the concept of film as a narrative link. It must also be noted that the integration of narrative components into a system for document access obviously entails a much higher grade of subjectivity than the retrieval of “pure data”. The proposed system can thus not replace, but rather provide an alternative to conventional models of information access. Nevertheless, the described weaknesses in the general concept of the document archive (see chapter 2.1.1) raise the question how “objective” any methods of information storage and -retrieval can be. In this context, the full transparency (open source) of the proposed open hypervideo system from interface to document architecture allows at least the distributed design of and control over its methodology.
As open video on the web develops further, there will have to be a stronger connection of the web developer community and existing multimedia research communities (Cesar et al., 2011). The ongoing integration of filmmakers into the field (as already proclaimed by the Popcorn Community) will also help to develop new forms of web-based film and hopefully entire novel genres.
Hypervideo in particular could become part of evolving web-based TV environments. Comparable to the advancements that the DVD brought to “traditional” video, TV-hypervideo could lead to the relocation of interactivity in forms of individual remote control apps. As such developments would still be part of the open web architecture, most certainly new possibilities will arise for media authors and developers to create, rebuild and remix the respective implementations. Openness on the code layer will also enable the development of additional interfaces that enrich existing media by communication and collaboration possibilities.
Supposing that something similar to the proposed model of non-linear narrative sequences (see chapter 3.2.1) finds its way to a broad use, there will finally be a chance to add direction and multiple destinations to the properties of a hyperlink. By following a certain path, the user could automatically create a filmic trail (see also chapter 2.2.1) of his or her individual hypervideo experience. Mechanisms that allow “recording” and sharing this trail could enable new forms of knowledge communication, e.g. users recording their trail and sharing it together with the insight that was gained from choosing this particular sequence of information. The trail could then be passively re-watched by another user to comprehend the emergence of a particular idea through all its stages. Such kind of recorded trails could also allow systems to be built that use quantitative information about the paths taken to dynamically guide the user through a web of hypervideo sequences by suggesting specific paths based on previous user interaction.
Finally, open source “development” of film in conjunction with improving automated media analysis and live object detection technology will offer new possibilities in terms of narrative generation. Such approaches could be used to generate additional “navigational bridges” (Shawney et al., 1996, see also chapter 3.2.1) where existing paths lead to dead ends, as well as to generate hypervideo contents from information sequences that already exist in other forms. However, the exploration of film for non-linear storytelling requires a conscious use of the technological possibilities.
Barthes, R. (1978). The Death of the Author. In Image, Music, Text. New York: Hill and Wang.
Berners-Lee, T. & Cailliau, R. (1990). WordWideWeb: Proposal for a HyperText Project. [http://www.w3.org/Proposal]. Retrieved 23/10/2011.
Bolter, J.D. & Gromala, D. (2003). Windows and Mirrors: Interaction Design, Digital Art and the Myth of Transparency. Cambridge/London: The MIT Press.
Bolter, J.D. & Grusin, R. (1999). Remediation: Understanding New Media. Cambridge/London: The MIT Press.
Bush, V. (1945). “As We May Think.” Atlantic Monthly 176 (1), 101-108.
Cesar, P., Ooi, W.T., Moskowitz, B., Babin, Z., Bulterman, D., Lienhart, R. & Richter, R. (2011). Towards synergy between the open source and the research multimedia communities. In Proceedings of the 19th ACM international conference on Multimedia (MM ‘11). New York: ACM.
Derrida, J. (1996). Archive fever - a freudian Impression. Chicago: The University of Chicago Press.
Diakopoulus, N., Luther, K., Medynski, Y.E. & Essa, I. (2007). Remixing Authorship: Reconfiguring the Author in Online Video Remix Culture. Technical Report, Georgia Institute of Technology.
Douglas, J.Y. (1991). Understanding the Act of Reading: the WOE Beginners’ Guide to Dissection. In Writing on the Edge, 2.2. University of California at Davis, 112-125.
Dörk, M., Carpendale, S. & Williamson, C. (2011). The Information Flaneur: A Fresh Look at Information Seeking. In Proceedings of the 2011 annual conference on Human factors in computing systems (CHI ’11). New York: ACM. 1215-1224.
Ebeling, K. (2009). Das Gesetz des Archivs. In Ebeling, K. & Günzel, S. (ed.) Archivologie. Theorien des Archivs in Wissenschaft, Medien und Künsten. Berlin: Kulturverlag Kadmos, 61-69.
Finke, M. (2005). Unterstützung des kooperativen Wissenserwerbs durch Hypervideo-Inhalte. Dissertation, TU Darmstadt.
Foucault, M. (1980). What is an Author? In Harari, J.V. (ed.) Textual Strategies: Perspectives in Post-structuralist Criticism. London: Methuen & Co. 141-201.
Guimarães, N., Chambel, T. & Bidarra, J. (2000). From cognitive maps to hypervideo: Supporting flexible and rich learner-centred environments. In Interactive Multimedia Electronic Journal of Computer-Enhanced Learning, 2 (2).
Hearst, M. (2009). Search User Interfaces. New York, NY: Cambridge University Press.
Hickson, I. (2011). HTML5 – A vocabulary and associated APIs for HTML and XHTML. Editors Draft. Technical Report. [http://dev.w3.org/html5/spec/Overview.html]. Retrieved 10/12/2011.
Kane, C. (2009). “The Question of Freedom at the Open Video Conference”. [http://rhizome.org/editorial/2009/jul/1/the-question-of-freedom-at-the-open-video-conferen/]. Retrieved 27/10/2011.
Landow, G.P. (2006). Hypertext 3.0 – Critical Theory and New Media in an Era of Globalization, 3rd Edition. Baltimore, Maryland: The John Hopkins University Press.
Lippman, A. (1980). Movie-Maps: An application of the optical video disk to computer graphics. In Proceedings of the 7th annual Conference on Computer graphics and Interactive techniques. Seattle, Washington. 32-42.
Hardman, L., Bulterman, D.C.A. & van Rossum, G. (1994). “The Amsterdam Hypermedia Model: Adding Time and Context to the Dexter-Model”. In Communications of the ACM, 37. 50-62.
Locatis, C., Charuhas, J. & Banvard, R. (1990). Hypervideo. In Educational Technology Research and Development, 38(2). 41-49.
Manovich, L. (2002). Who is the Author? Sampling / Remixing / Open Source. [http://www.manovich.net/DOCS/models_of_authorship.doc]. Retrieved 26/10/2011.
Michon, B. (1993). Hotspots. In M.E. Hodges & R.M. Sasnett (ed.) Multimedia Computing. Reading, MA: Addison-Wesley. 219-227.
Nelson, T.H. (1993). Literary Machines. Sausalito, CA: Mindful Press, Edition 93.1.
Nelson, T.H., Smith, R.A. & Mallicoat, M. (2007). Back to the Future: Hypertext the Way It Used to Be. In Proceedings of the 18th ACM Conference on Hypertext and Hypermedia (HT ‘07). New York: ACM, 227-228.
Nielsen, J. (1999). Designing Web Usability. Indianapolis: New Riders Publishing.
Norman, D. (1998). The Invisible Computer. Cambridge, MA: The MIT Press.
Oliver, H., Eng, N. & Aurisicchio, M (2011). Using Bidirectionally Hyperlinked Concept Maps To Analyze Nonlinear Narratives. In Proceedings of ACM Hypertext ’11. New York: ACM.
Paivio, A. (1986). Mental representation: A dual coding approach. Oxford, UK: Oxford University Press.
Ricoeur, P. (2009). Archiv, Dokument, Spur. In Ebeling, K. & Günzel, S. (ed.) Archivologie. Theorien des Archivs in Wissenschaft, Medien und Künsten. Berlin: Kulturverlag Kadmos, 123-137.
Rieger, M. (2009). Anarchie im Archiv. Vom Künstler als Sammler. In Ebeling, K. & Günzel, S. (ed.) Archivologie. Theorien des Archivs in Wissenschaft, Medien und Künsten. Berlin: Kulturverlag Kadmos, 253-269.
Rushkoff, D. (2010). Program or Be Programmed: Ten Commands for a Digital Age. New York: OR Books.
Sadallah, M., Aubert, O. & Prié, Y. (2011). Component-based Hypervideo Model: High-Level Operational Specification of Hypervideos. In Proceedings of DocEng ’11. Mountain View, CA: ACM. 53-56.
Schwan S. & Riempp, R. (2004). The cognitive benefits of interactive videos: Learning to tie nautical knots. In Learning and instruction, 14 (3), 293-305.
Shawney, N., Balcom, D. & Smith, I. (1996). HyperCafe: Narrative and Aesthetic Properties of Hypervideo. In Proceedings of the Seventh ACM Conference on Hypertext. New York: ACM. 1-10.
Shipman, F., Girgensohn, A. & Wilcox, L. (2003a). Hyper-Hitchcock: Towards the Easy Authoring of Interactive Video. In Human-Computer Interaction INTERACT ’03. IOS Press. 33-40.
Shipman, F., Girgensohn, A. & Wilcox, L. (2003b). Combining Spatial and Navigational Structure in the Hyper-Hitchcock Hypervideo Editor. In Proceedings of HT ’03. Nottingham, UK: ACM.
Simanowski, R. (2001). “Autorschaften in den digitalen Medien. Einleitung.”. Text & Kritik. Zeitschrift für Literatur, Nr. 152.
Spiro, R. J. & Jehng, J. C. (1990). Cognitive flexibility, random access instruction, and hypertext: Theory and technology for non-linear and multidimensional traversal of complex subject matter. In Nix, D., Spiro R. J., Hillsdale, N.J. (ed.) Cognition, Education, and Multimedia: Exploring Ideas in High Technology. Lawrence Erlbaum, 163-205.
Surman, M. (2011). “Definitions: media, freedom, web”. [http://commonspace.wordpress.com/2011/01/31/mediadefinitions/]. Retrieved 27/10/2011.
Troncy, R., Mannens, E., Pfeiffer, S. & van Deursen, D. (2011). Media Fragments URI 1.0. W3C Candidate Recommendation. Technical Report. [http://www.w3.org/TR/2011/CR-media-frags-20111201/]. Retrieved 10/12/2011.
Waitelonis, J. & Sack, H. (2011). Towards exploratory video search using linked data. In Multimedia Tools and Applications, 53. Springer Netherlands. 1-28.
Watercutter, A. (2011). “Premiere: One Millionth Tower High-Rise Documentary Takes Format to New Heights“. [http://www.wired.com/underwire/?p=83829]. Retrieved 04/12/2011.
Wilson, M.L., Kules, B., schrafel, m.c. & Shneiderman, B. (2010). From Keyword Search to Exploration: Designing Future Search Interfaces for the Web. In Foundations and Trends in Web Science, 2(1). 1-97.
Winzen, M. (1997). Sammeln – so selbstverständlich, so paradox. In Schaffner, I. & Winzen, M. (ed.) Deep Storage. Arsenale der Erinnerung. Sammeln, Speichern, Archivieren in der Kunst. München: Prestel Verlag.
Wirth, U. (1997). Literatur im Internet. Oder: Wen kümmert’s wer liest? In Münker, S. & Roesler, A. (ed.) Mythos Internet. Frankfurt: Suhrkamp.
Zahn, C. (2003). Wissenskommunikation mit Hypervideos. Münster: Waxmann Verlag